
01 멘토 소개

김창현
•
AIX 미래 R&D, BioMedical AI 팀 소속
•
현재 진행 연구 (BioMedical AI)
◦
이빈인후과 음성 질환 모델 개발
◦
방사선 의료 영상 분류 모델 개발
•
이전 진행 연구
◦
Music AI(가창 모델 합성, 자동 피아노 기보 등)
◦
Multimodal AI(음성-텍스트 기반 감정 인식)
◦
CV(자율 주행 Sensor Configuration, 보행자 인식 등)

이상율
•
AIX 미래 R&D, BioMedical AI팀 소속
•
현재 진행 프로젝트
◦
반려동물 영상진단 AI 모델 개발과제 참여중
•
이전 진행 연구
◦
음성데이터를 통한 스트레스 진단 AI모델 개발
◦
2020년까지는 T map 기술 개발팀에서 근무함.
02 프로젝트 소개
의료 영상 (X-Ray) 데이터의 경우 양질의 레이블 데이터가 고비용의 문제로 인해 부족한 현실입니다.
데이터가 부족한 상황에도 상용화 레벨의 성능 좋은 딥러닝 모델을 이용한 자동 진단 기술의 수요는 최근 정점에 이르렀습니다.
이에 최신 딥러닝 학습 기법 중 Self-supervised (+ semi-supervised) 방식으로 많은 양의 Un-labeled 의료 데이터로 좋은 Representation을 우선 만들고 이를 원하는 target downstream task에 활용하는 방안에 대한 연구를 본 연구에서는 우수한 학생들을 모시고 창의적인 ideation을 통해서 진행해보려고 합니다.
데이터 사용 전략 부터 meta architecture 모델링까지 다양한 연구들을 SKT 연구원과 함께 진행하여 실제로 사용할 수 있는 연구 성과를 도출하고자 합니다.
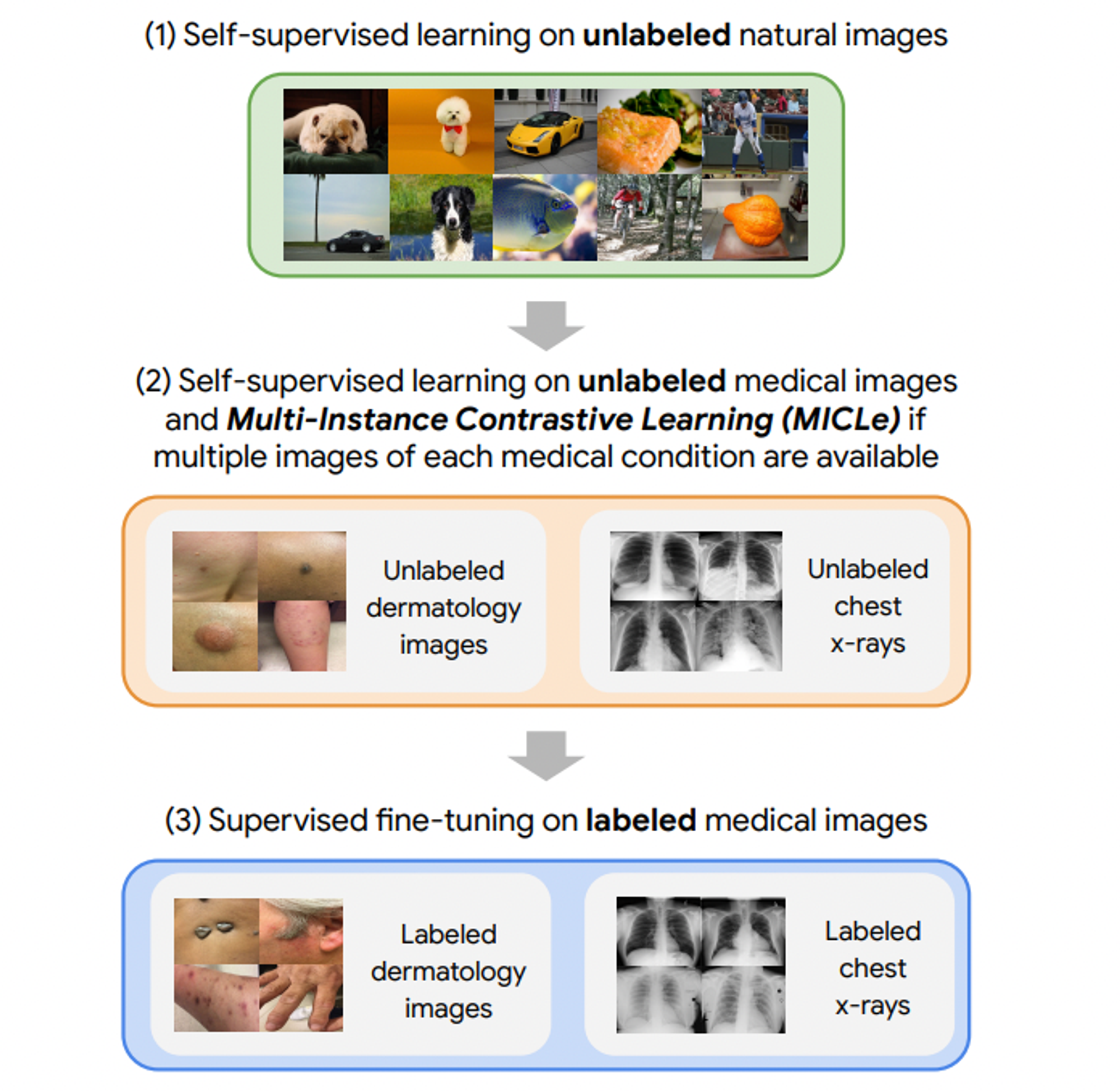
위 연구는 Google Research and Health 에서 진행했던 “Big Self-Supervised Models Advance Medical Image Classification” 연구 입니다. 여기에서 보는 것처럼 적은 양의 데이터로 Supervised 학습을 하는 것 보다는 다양한 영상 이미지를 활용한 Self-supervised 방식이 몇몇 의료 영상 분석에 더 좋은 representation learning 방법이라는 것을 실험 적으로 확인 할 수 있습니다.
[참고 1] Azizi, Shekoofeh, et al. "Big self-supervised models advance medical image classification." Proceedings of the IEEE/CVF International Conference on Computer Vision
. 2021.
[참고 2] Gong, Yuan, et al. "Ssast: Self-supervised audio spectrogram transformer." Proceedings of the AAAI Conference on Artificial Intelligence
. Vol. 36. No. 10. 2022.
이에 Self-supervised (혹은 Semi-supervised) 방법에 대한 다양한 연구들을 분석하여 SKT 연구진과 함께 새로운 의료 영상 SOTA 모델 개발해 보실 분들을 모셔 보고자 합니다.
03 이런 Fellows를 찾습니다
•
Computer Vision modeling 다수 경험자
•
의료 영상 도메인 친숙 하신 분 (혹은 부담감이 없으신 분들)
•
Self-supervised 방법에 대한 흥미도가 높은 연구 유경험자
FAQ
Q) 현재 SKT에서 진행하고 있거나/계획 중인 과제가 무엇인지 알 수 있을까요? 정상/비정상 진단과 관련한 문제인지, 분류 문제인지 궁금합니다.
A) 본 과제는 SKT BioMedical AI 팀에서 X-Caliber 라는 수의 영상 프로젝트와 연계되어 진행되는 것으로 멀티 클래스 분류 문제라고 보시면 됩니다.
Q) 본 과제에서 어떤 데이터 셋을 활용할 수 있나요?
A) 다양한 질환 X-Ray 데이터 셋 들이 있을 텐데요, 현재는 Public Open된 모든 데이터 셋을 활용할 생각입니다.
최종 타깃 데이터 셋은 AI Hub 수의 근골격 질환 MSK 데이터 셋을 활용할 예정 입니다.
Q) 위에서 언급된 ‘AI Hub 수의 근골격 질환 MSK 데이터 셋’은 정확도 측정을 진행하는지,
또한 이 데이터 셋은 Test Set 용도인지, Validation Set 혹은 Training Set으로 사용가능한 것인지 궁금합니다.
A) AI Hub 근골격 질환 데이터 셋을 열어보면 Train/Validation 데이터가 들어 있습니다.
Self-supervised 방법으로 사전학습과 미세 학습을 진행하기 때문에 다양한 데이터 셋에 대해서 사전 학습을 진행 할 수 있으며,
사용 방법에 대해서도 성능 향상을 위해 다양한 전략이 나올 수 있습니다.
이에 지원자분들께서는 가능하시면 많은 X-Ray image dataset (인의와 수의 제한을 두지 말고 직접 다운 받아 안을 들여다 보시면 됩니다)을 찾아보시고,
활용 방안에 대해 전략을 어떤 Step으로 진행하겠다는 이론과 실험 경험치들을 학습 계획에 잘 녹여
curriculum learning/stagewise learning 방법에 대해 고민해 주시길 바랍니다.
첨언을 드리면 MSK의 경우 인의 데이터 셋 (MURA: Stanford Univ. 등) 도 많은 종류가 오픈되어 있습니다.
Q) 본 과제가 분류 문제라면 어떤 질환들에 대한 데이터들을 분류하는지 알고 싶습니다.
A) 근골격 질환 종류 7종을 생각하고 있으며, 이 7개 질환의 binary classification이 진행될 예정입니다.
다만 class 별 정상/비정상의 데이터 사이즈 차이가 매우 크기에, 먼저 전체 데이터셋에 대해 binary로 정상/비정상을 풀고
다시 class별 binary를 푸는 sequential classfication을 고려했습니다. 환부에 대한 인식은 아닙니다.
Q) 보다 세부적이고 자세한 연구 계획서를 작성하기 위한 조언을 얻을 수 있을까요?
A) 현재 엑스레이 데이터가 다양하게 많이 나와 있는데요,
(1) 사용 데이터 선택, (2) 자기 주도 학습 (Self-supervised learning)의 데이터 별 학습 전략 (사전 학습 & 미세 학습), (3) 모델 개선 포인트
이 세 가지에 대해 어떻게 접근해서 상용화 수준 성능을 만들어 보겠다는 스토리로 가능한 구체적인 실험 계획 설명이 있다면 좋겠습니다.
특히 왜 그렇게 실험 설계를 하였는지에 대한 논리가 중요합니다.
Q) 위 질문에서 말하는 ‘데이터 별 학습 전략은 구체적으로 어떤 것을 의미하는지요?
A) Self-supervised learning의 경우, base network을 대량의 데이터 (Unlabeled 수백만장)은 Self-supervised 사전 학습과
특정 타깃 (Labeled 수 만~수 십만)은 Finetunning 학습으로 나누어 진행되어야 합니다.
여기에 사용하는 다양한 데이터와 그 데이터의 종류에 대한 기획을 어떻게 기획할지부터 연구 계획서에 담아주시면 됩니다.
Curriculum learning, Distribution shift 등이 Key point가 될 수도 있겠습니다.
Q) X-Caliber 라는 수의 영상 프로젝트의 목적은 '수의' 영상 데이터를 넘어 펫 케어 서비스 제공 및 동물 복지 향상이라고 알고 있습니다.
이에 본 과제에서 동물을 메인으로 해야하는지, 의료 영상(동물, 사람)으로 해야하는지, 또는 사람에 도움이 되는 부분까지의 고려 등
어떤 목적에 포커싱하여 진행하면 될지 궁금합니다.
A) 저희 멘토들은 현업에서 X-Caliber 과제와 펠로우십 과제를 함께 진행하고 있습니다.
이에 X-Caliber 과제와 펠로우십 과제가 연계되어 있다는 것이지, 펠로우십 연구를 통한 결과물을 상용화에 바로 쓰겠다는 것은 아닙니다.
상용화를 위해서는 상당히 많은 검토와 오랜 시간이 소요되며 실제 정부 기관의 인준 과정이 진행 되어야 하므로 바로 결과물을 적용하기도 어렵습니다.
이에 다양한 의료 영상 과제 (인의 혹은 수의)의 base network로 활용 가능하다는 정도로 이해해 주시면 되겠습니다.
본 연구 과제를 통한 결과물이 상용화까지 진행되지 않을 수도 있지만 멘토와 펠로우간 협의를 통해 SOTA (State of the Art) 모델을 먼저 만들고
국내외 학술 대회 논문과 특허, Challenge에 나가 활용 가능성을 먼저 타진해 볼 수 있습니다.
이때 논문과 특허의 경우 SKT가 저작권 (교신저자, 특허권 등)을 갖습니다.