

01 멘토 소개
.png&blockId=42c60921-b82c-4691-be54-d9f29cb93431)


홍태희
•
Infra Data플랫폼팀
•
Data Engineer, LLM Application Engineer
•
SK텔레콤의 통신 도메인 Datalake 와 Data 분석환경 서비스를 개발 운영하고 있습니다.
안태형
•
Infra Data플랫폼팀
•
Data Engineer, LLM Application Engineer
•
SK텔레콤의 통신 도메인 Datalake 와 Data 분석환경 서비스를 홍태희님과 함께 개발 운영하고 있습니다.
오지연
•
AI Data 개발팀
•
ML Engineer
•
RAG/LLM 모델 파인튜닝
•
AI 관련 특허 (1020190044262, 1020200079226, 1020200073334, 1020200071007)
정영윤
•
AI Data 개발팀
•
Data Engineer
•
MLOps
02 프로젝트 소개
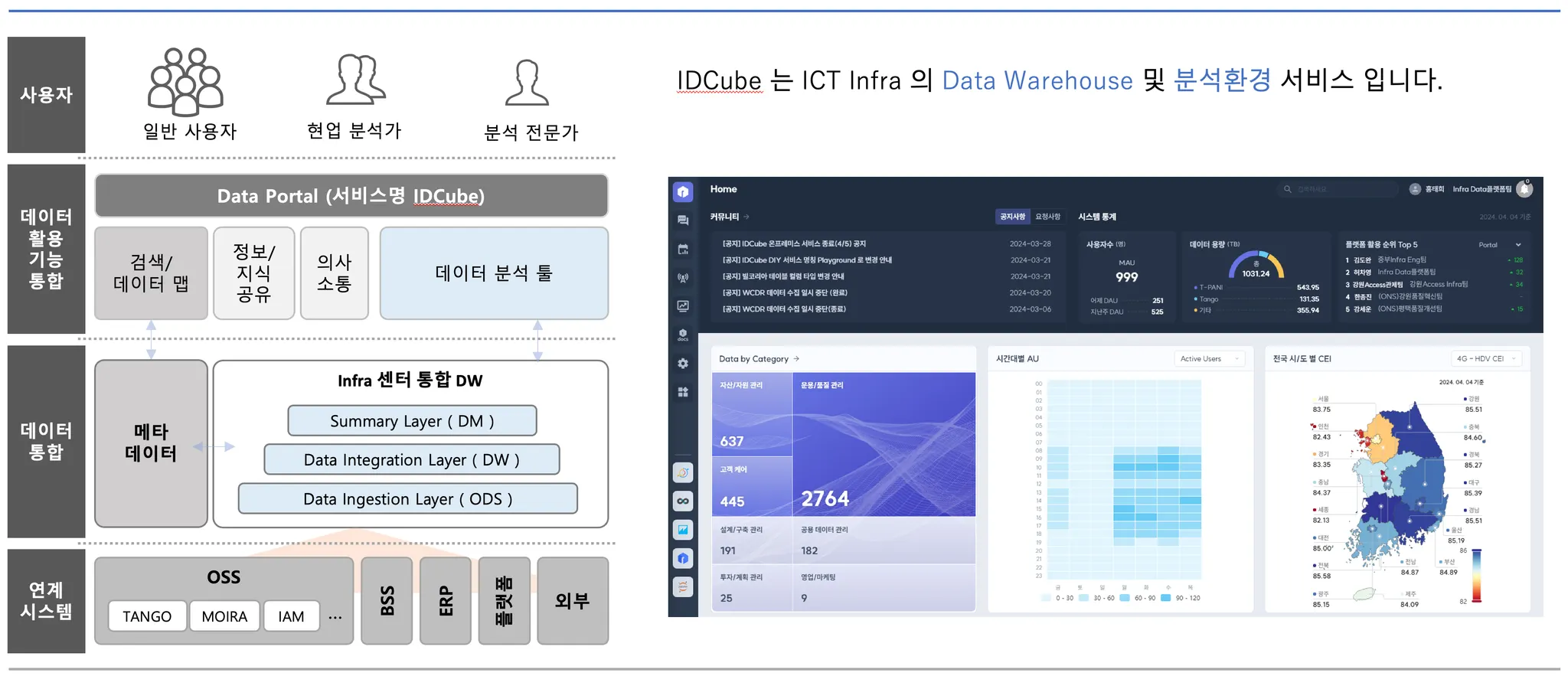
데이터분석하는 AI 챗봇 서비스 구현
우리의 프로젝트의 최종 목표는 생성형 AI를 이용하여 데이터를 분석해주는 AI 챗봇 서비스를 구현하는 것 입니다. IDCube 는 SK텔레콤의 통신 데이터를 저장하는 Datalake 역할과, 구성원에게 데이터를 분석할 수 있는 환경을 제공하는 사내 서비스이며, 구현된 챗봇 서비스는 실제 프로덕션 레벨로 사용될 수 있습니다.
 프로젝트의 아키텍처와 구현 요소
프로젝트의 아키텍처와 구현 요소
챗봇 서비스 아키텍처
저희가 구현하고자 하는 AI챗봇 서비스의 아키텍처는 아래와 같이 2가지 영역으로 구분됩니다.
1.
RAG 기반 프롬프트 엔지니어링 영역
2.
오프라인 LLM 파인튜닝 영역
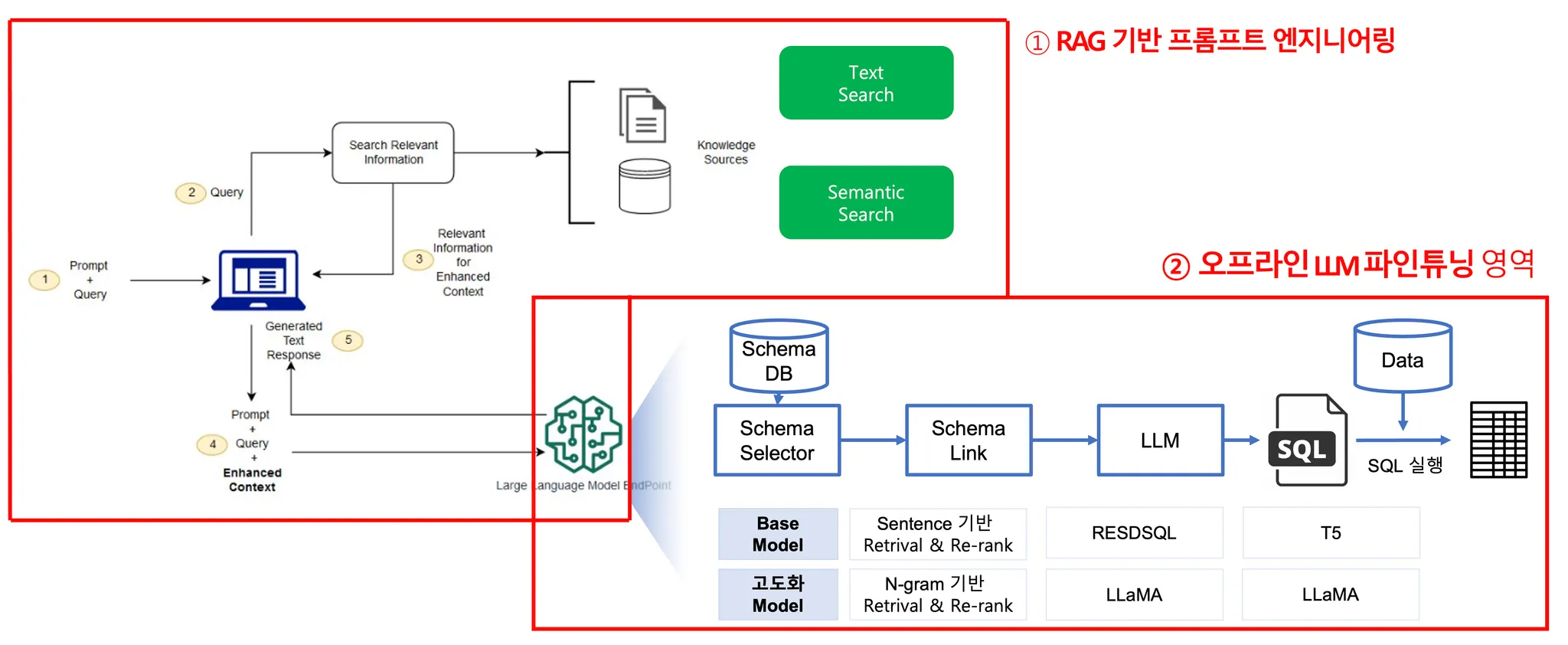
1. RAG 기반 프롬프트 엔지니어링 영역
•
LLM 에 정보를 전달하기 전, 사용자 질의 내용(보통 대충 질문함)을 LLM 이 이해하고 SQL 을 생성할 수 있는 형태로 만들어주기 위한 SQL 지식DB 를 구축 합니다. (구축 진행중)
•
구축된 지식DB 의 데이터에 대한 RAG 시스템(Lexical, Semantic 하이브리드)을 구현합니다. (구현 진행중)
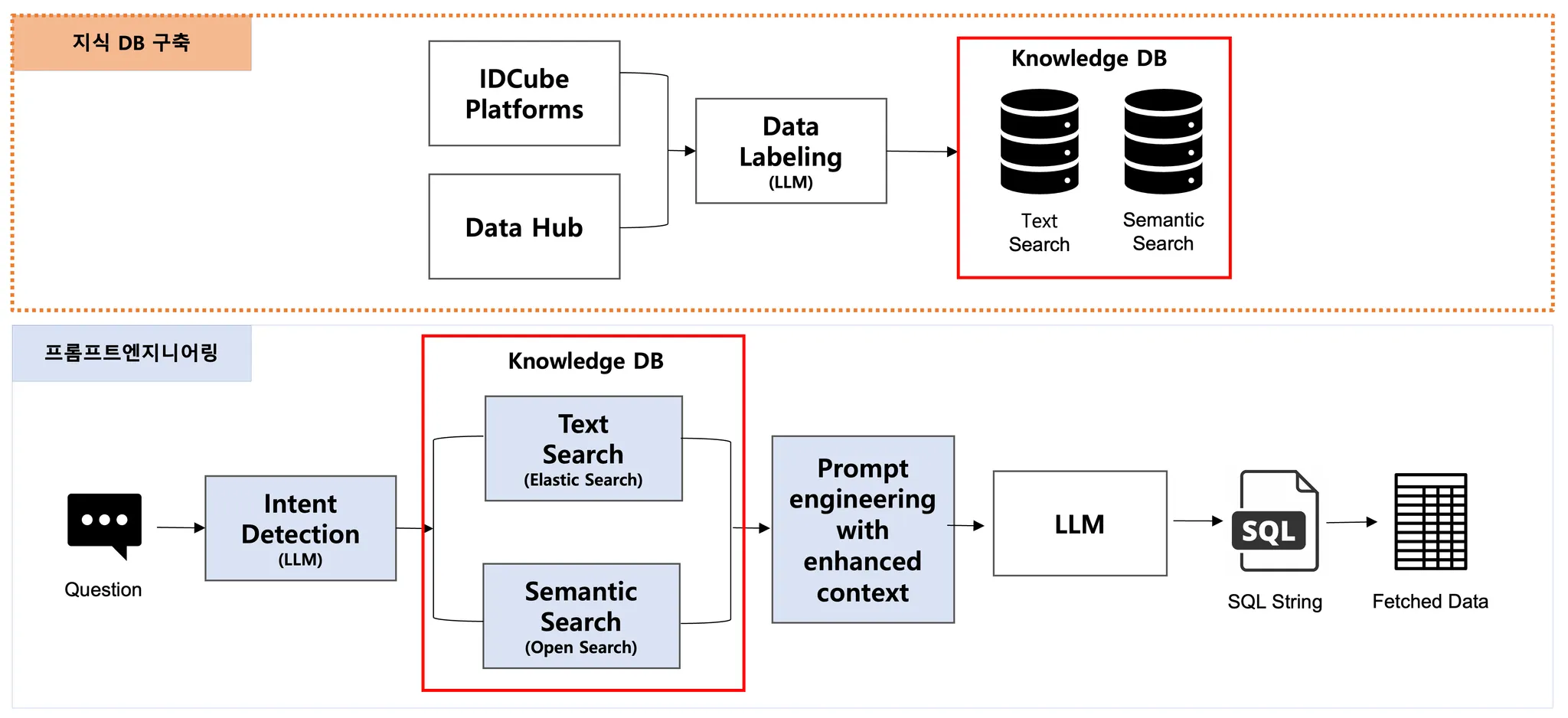
•
아래는 실제 데이터가 조회되는 과정을 간단하게 Flow 로 표현해낸 예제 입니다.
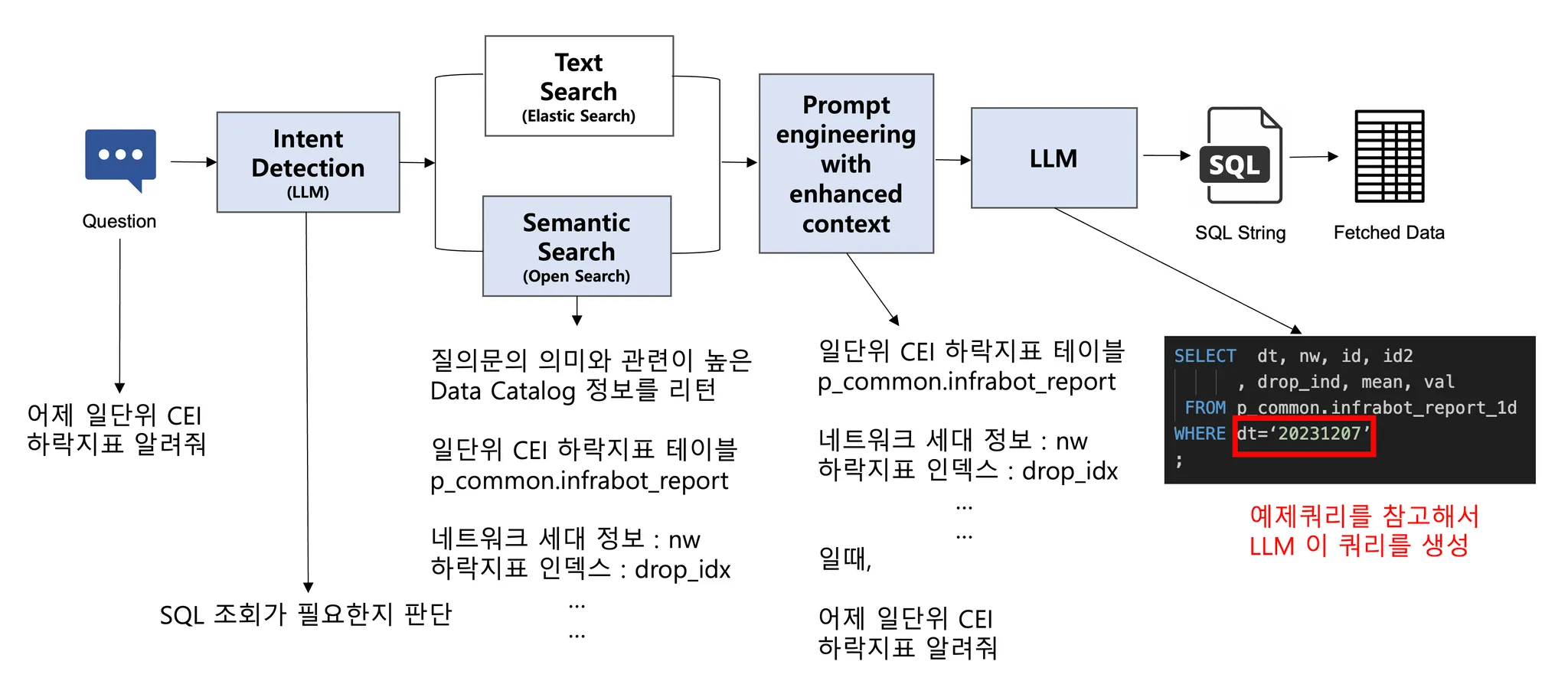
•
서비스 구현을 위해 아래와 같은 기술스택을 사용합니다.
◦
AWS : 서비스 구현은 로컬(개발) → AWS 의 스테이징/상용 서비스로 배포 됩니다.
◦
Ollama : 모델 서빙 및 챗봇 웹서비스
◦
Langchain : LLM Applcation 개발을 위해 랭체인 프레임워크를 사용하며, 일부 부족한 부분은 직접 구현합니다.
◦
ElasticeSearch : Lexical(Text) Search 를 위해 엘라스틱서치를 사용합니다.
◦
OpenSearch & Milvus : Semantic Search 구현을 위해 AWS OpenSearch 및 Milvus Vector DB 를 사용합니다.
◦
그 외 다양한 기술스택에 대한 경험을 하실 수 있습니다.
2. 오프라인 LLM 파인튜닝 영역
하지만 아래와같은 이유로 이런 모델들은 실무에 사용이 불가합니다.
•
공개된 자연어 SQL 관련 논문/모델은 모두 RDB 기반 소규모 데이터
◦
실무 데이터는 foreign key가 없고, partition key를 사용하는 hive 기반 데이터
◦
RDB는 데이터베이스 안에서만 join 하지만, 실무 데이터는 join 범위 제한 없음
•
모든 DB 스키마 정보를 모델 입력에 제공하는 경우 다수 존재
◦
공개 데이터셋은 테이블과 컬럼 개수가 작아서 가능 (테이블당 컬럼 평균 약 8개)
◦
실무 데이터는 테이블당 컬럼 평균 150개라서 모든 스키마 정보를 제공하는게 불가능
•
공개된 학습용 데이터는 테이블명/컬럼명 명확하고 직관적
◦
공개된 학습 컬럼명 예시: employee_name, nationality, first_name…
◦
실제 컬럼명 예시: qos_qoe1, eqp_id, accum_lte_tot…
•
보안 이슈
◦
보통 기업 내의 데이터는 정보유출의 보안 이슈로 인해 ChatGPT 와 같은 API 모델을 사용할 수 없음
현재까지 저희가 작업하고있는 내용은 아래와 같습니다.
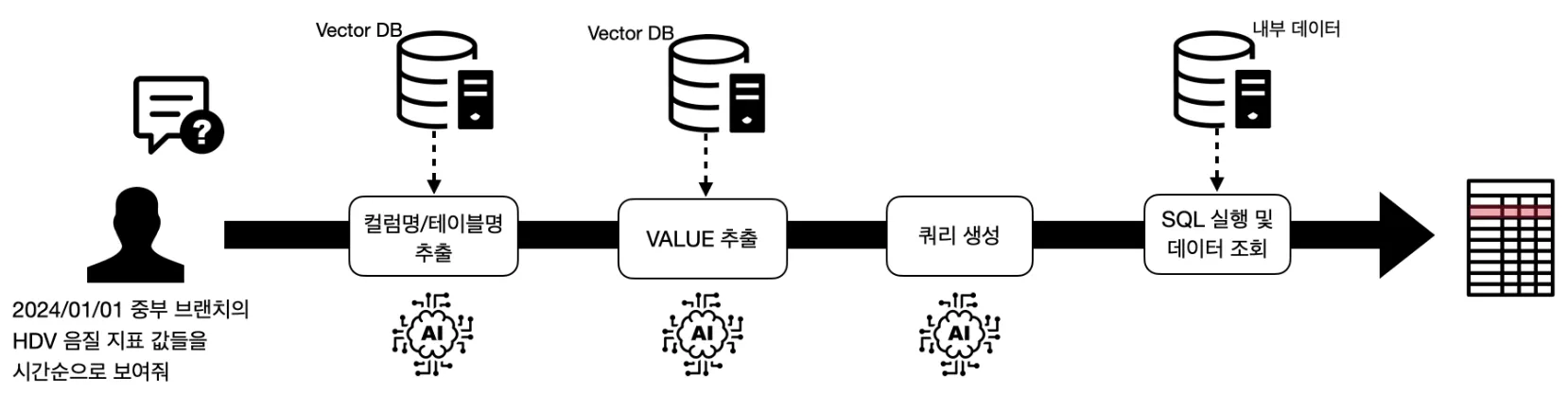
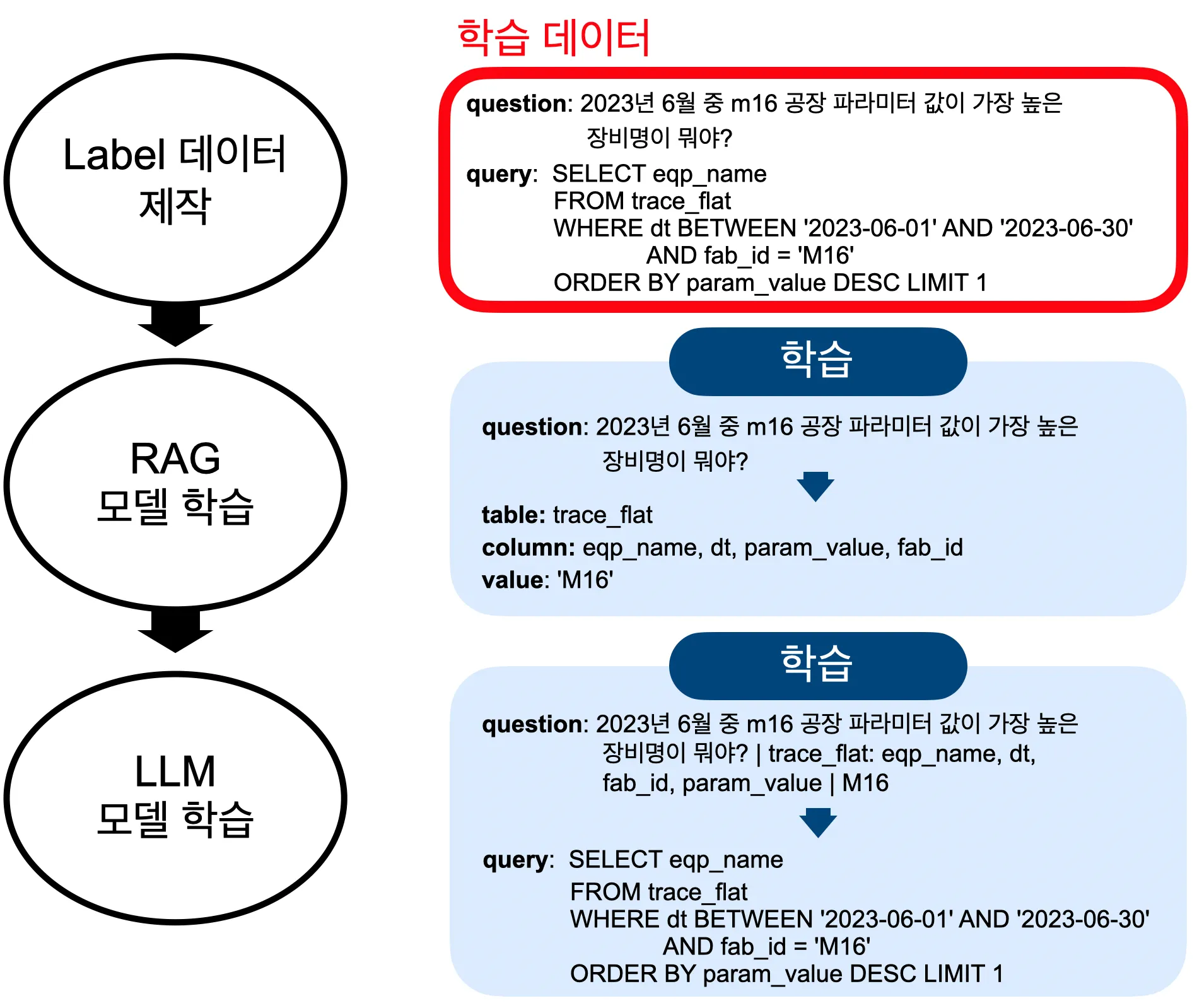

RAG에서 미리 전체 테이블의 스키마 정보와 도메인 지식을 학습하여 질의문을 받을 때 해당 질의문이 어느 테이블, 컬럼과 연관이 있는지를 찾아내야 합니다. 모든 스키마를 다 준다면 당연히 잘 동작하겠지만, LLM 모델의 토큰 사이즈가 제한이 있고 학습 리소스가 제한적이기 때문에, 가장 연관있는 테이블과 컬럼 몇개만 추려내는 과정입니다.
이후 LLM 모델에서는 질의문과 RAG의 결과물을 입력받아서 sql generation을 하도록 파인튜닝을 합니다. 현재까지 여러가지 LLM 모델을 비교해본 결과 KOSOLAR가 가장 성능이 좋았습니다.
한글 Text2SQL 데이터셋 대상으로 EM/BLEU 점수가 약 72%, 90% 정도 나오지만, SKT 데이터 대상으로는 많이 부족한 상태입니다.
RAG, LLM 혹은 데이터 전치리 과정 등 개선할 수 있는 포인트는 많습니다. 과제를 하게 된다면 저희가 생각한 개선점들을 함께 시도해보고 더 나은 방법을 찾아볼 수도 있고, 혹은 여러분들이 새로운 방법을 개발해서 모델 성능을 개선시켜도 좋습니다.
이 과제를 통해서 대규모 데이터를 활용한 모델 학습 경험, 실무 데이터의 특징으로부터 발생하는 문제점들을 해결하는 경험을 할 수 있는 계기가 되었으면 좋겠습니다
또한 기존 기술들이 모두 소규모 RDB인 점을 고려하면, 대규모 데이터로 새로운 기술을 만들어서 특허 또는 논문도 작성할 수 있을거라 생각합니다.
03 이런 Fellows를 찾아요!
우리가 찾는 사람:
•
프로젝트의 범위가 넓기 때문에, 진행중인 내용을 이해하고 Generative AI(Applcation) 혹은 Generative AI (Model) 영역 중 관심 있는 파트를 멘토들과 논의하여 챗봇 서비스 구현에 기여할 수 있는 분을 찾습니다.
(양쪽 다 관심 있어도 됩니다. 멘토들과 상의하여 연구주제를 결정합니다.)
•
SQL 과 Python 언어를 다룰 수 있는 사람을 찾습니다.
•
새로운 것을 학습하는 것에 두려움이 없고 열정적인 분을 찾습니다.
우대 사항
•
LLM 애플리케이션 개발 및 파인튜닝 유경험자
•
논문 투고 혹은 특허 제출해본 개발경험
•
Svelte 웹 애플리케이션 개발경험
FAQ
Q1. 과제의 내용을 봤을 때 대량의 데이터가 있다는 것은 알 것 같은데요.
이후 실제 프로젝트를 하게 된다면 추가적으로 데이터를 만들어야 할 경우도 생기는지 궁금합니다.
A1. RAG 의 성능을 높이기 위한 메타정보를 생성하는 부분이 있습니다. 다만, 이 부분도 Human Resource 가 아닌 LLM 을 활용하는 방향으로 적용 진행 중 입니다. 프로젝트 진행 과정의 중요한 성공요소를 Human Resource 최소화에 두고 있습니다. 따라서, 일부 검증을 위한 판단 요소를 제외하면 자동화를 하거나 LLM 을 활용하는 방향으로 검토합니다.
Q2. Svelte 개발 경험을 우대한다고 되어있는데 기존에 다른 프론트 개발을 한 적이 있다면 그 프레임워크로 사용할 수도 있는지 궁금합니다.
A2. 전체 서비스에서 웹 애플리케이션 형태로 개발이 될 필요가 있는 몇가지 유형의 대상이 있습니다.
- 1) 서비스용 챗봇 웹애플리케이션
- 2) 지식 DB 관리자 웹애플리케이션
- 3) LLM Ops 를 위한 Playground 웹애플리케이션 등
현재 1번을 Svelte 를 기반으로 한 오픈소스로 진행하고 있기 때문에 우대사항에 적어두었고, 2~3번은 Streamlit, Gradio 등 자유롭게 구성하고 있습니다. (프레임워크 의존도 없음, 변경가능)
Q3. 프로젝트의 목표가 텍스트를 쿼리문으로 잘 작성하여 원하는 데이터를 가져오는 것으로 알고 있습니다. 이 과정에서 Model에 관한 연구는 당연히 원하는 성능을 달성하기 위한 프레임워크 연구 및 개발로 생각하고 있습니다. Application에 대해서 연구를 한다면 어떻게 진행이 된다는 이야기인지 조금 더 설명을 해주실 수 있나요?
A3.
LLM Application 개발을 크게보면 1) RAG 기반의 프롬프트 엔지니어링과 LLM 파인튜닝 영역으로 나누어 진행하고 있습니다.
LLM 파인튜닝만으로는 원하는 성능의 SQL 생성이 어렵고, 지식DB 검색을 기반으로한 RAG 성능 최적화(프롬프트 엔지니어링 포함)를 진행해야 합니다. 몇가지 주요 태스크들을 정리하면 아래와 같습니다.
- 지식DB 생성 및 구축 파이프라인 개발(이미 개발 진행중이고, 어느정도 구성이 되어 있음)
- 검색을 위한 지식DB 색인 및 임베딩 (도메인 특화된 임베딩 성능 최적화 포함)
- Lexical Search (ElasticSearch), Semantic Search (Milvus) 등 검색기능 구현 및 검색 성능 최적화
- 사용자 질의 의도 파악 및 CoT 구성
- LLM Ops 평가 체계 구성 (사용자 피드백 로깅 및 정확도 관리를 위한 개발)
- LLM 답변에 대한 웹 애플리케이션 커스터마이징 개발 (파일 다운로드 기능, 차트로 표현하는 기능 등)
이 외에도 많은 영역이 있을 수 있습니다.