
01 멘토 소개


•
Contact AI개발팀/Media R&D/GST
•
AI/DevOps 엔지니어
기타 (연구 성과/특허 경험 등)
•
Network Security 전공
•
Public Cloud 솔루션 아키텍처 설계/개발
(검은사막 모바일, C-ITS HDMap, SKT JumpAR)
•
AICC 플랫폼 설계/개발 (AI 챗봇)
•
Contact AI개발팀/Media R&D/GST
•
AI/DataOps 엔지니어
기타 (연구 성과/특허 경험 등)
•
Storage QoS 전공
•
Data Processing 엔진 개발
◦
DPA-A(Data Processing Accelerator)
◦
LightningDB(Custom Redis & RocksDB)코어 개발
•
AICC 플랫폼 데이터 파이프라인 설계/개발
02 프로젝트 소개
최근 LLM 을 활용한 다양한 애플리케이션들이 급부상하고 있고, CPU 환경에서도 동작 가능한 1B~7B의 경량화된 Local LLM에 대한 관심도가 증가하면서, RAG에 최적화된 LLM 모델을 이용한 챗봇, Autonomous Agent (e.g AutoGTP) 기술에 대한 관심이 증가하고 있습니다.
RAG(Retrieval-Augmented Generation)는 사용자의 방대한 지식(Knowledge Base) DB에서 시멘틱 서치하고, LLM이 정확하고 일관성 있는 답변을 생성하기 위해 필요한 맥락(Context) 정보로 활용하여 Prompt Injection 하는 방법입니다. 이는 방대한 지식에서 원하는 정보를 빠르게 찾고, 동시에 hallucination 문제를 해결하는 장점이 있습니다.
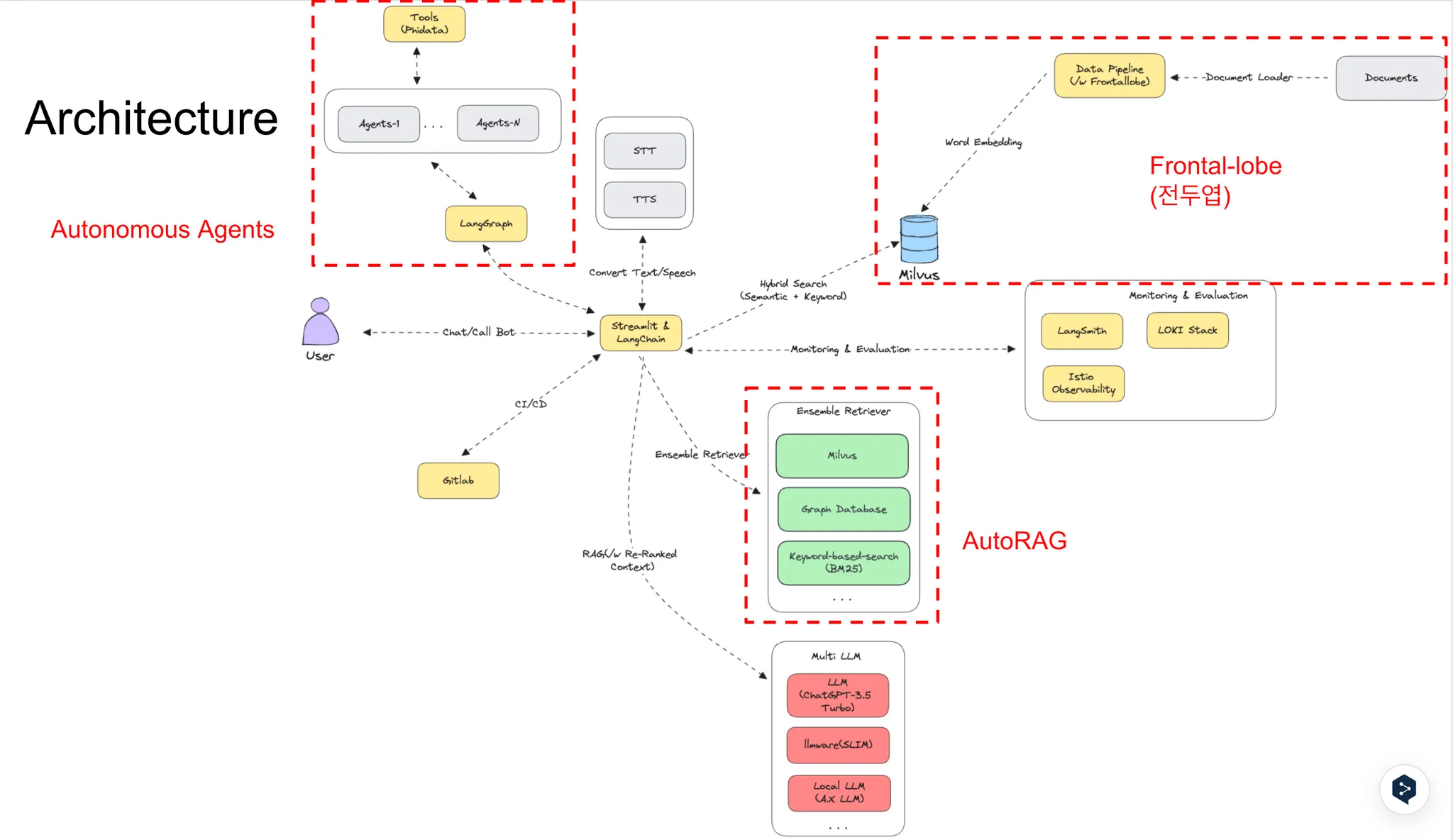
현재 SK Devocean(https://devocean.sk.com) 사이트에 RAG 기반의 챗봇을 팀내 자체 개발하여 런칭 예정중에 있습니다. (하단 아키텍처 참고)
챗봇 고도화 항목 중, 본 과제는 AutoRAG 도입을 통해 사용자에게 할루시네이션 없이 정확하고 일관성 있는 답변을 생성하기 위한 최적화된 RAG 파이프라인을 자동으로 생성하는 기술에 집중합니다.
우리가 발견한 문제점은?
문제인식의 시작점은 단순한 RAG (베이스라인 RAG)를 챗봇에 적용할 경우 사용자 의도에 부합하는 맥락 전달이 안되어 원하지 않는 엉뚱한 답변이 생성되는 경우가 많다는 것입니다. 이러한 현상의 가장 큰 원인은 원천 데이터의 퀄리티와 데이터 종류의 특성에서 찾을 수 있습니다.
첫번째로 데이터의 퀄리티는 너무나 중요합니다. 딥러닝 모델 학습 과정에서 “쓰레기 데이터로 학습시키면 쓰레기 결과가 나온다” 라는 말이 있습니다. RAG 에서도 동일한 법칙이 적용되는데요, 아무리 좋은 Embedding 모델과 Vector DB 를 사용해서 시멘티 서치한 결과를 맥락으로 뽑아내도 원천 데이터가 쓰레기 데이터라면 RAG의 성능은 좋을 수가 없습니다. 따라서 우리는 고객의 다양한 데이터를 정제하여 Vector DB를 KB(Knowledge Base) 활용하기 위한 데이터 파이프라인 자동화를 구축하고 있습니다. (Frontal-lobe 전두엽 프로젝트)
두번째로 현재 수많은 RAG 파이프라인과 모듈이 시중에 나와 있지만, 어떤 RAG 파이프라인이 "고객의 데이터셋"과 "사용 사례"에 적합한지 알 수 없다는 것입니다. 이를 위해 모든 데이터셋 종류마다 RAG 모듈을 만들고 평가하는 것은 매우 어려운 일입니다. 하지만 이러한 업을 수행하지 않으면 최적의 RAG 파이프라인을 찾지 못하고, 결국 사용자의 질의에 대해 의도하지 않거나 잘못된 정보가 생성되는 문제가 발생합니다.
문제점을 정리해보면,
•
토이 프로젝트 수준의 RAG 파이프라인(베이스라인)을 쉽게 만들 수 있지만, 실제 데이터와 사용 목적에 맞는 높은 성능의 RAG 파이프라인을 구성하는 것은 어려운 일임.
•
RAG는 데이터와 목적에 따라 어울리는 조합이 모두 다르며 최적의 조합을 찾기 위해서는 많은 실험과 평가를 반복해야하는 시간과 노력의 싸움임.
우리가 해결하고자 하는 것은?
위의 첫번째 문제는 팀내 별도 진행중인 전두엽(Frontal-lobe) 프로젝트를 통해 해결하고자 하고, 이번 과제에서는 두번째 문제를 해결하는데 집중하고자 합니다.
두번째 문제해결을 위해 AutoRAG 기술을 도입하고자 합니다. AutoRAG 기능을 통해 고객의 자체 평가 데이터셋(정답지 데이터셋: Query & Answer) 을 이용하여 다양한 RAG 모듈을 활용하여 자동으로 평가하고, 사용 사례에 가장 적합한 RAG 파이프라인을 찾을 수 있습니다. 그리고 최적의 RAG 파이프라인을 이용하여 AI 애플리케이션에 적용하여 정확하고 일관성 있는 답변을 생성할 수 있습니다.
결국 AutoRAG 기술을 적용하여 고객의 다양한 데이터세에 최적화된 RAG 파이프라인을 찾아내고, 이를 챗봇에 적용하여 생성되는 응답에 대해 평가/모니터링 솔루션 구축하여 AutoRAG 성능효과를 증명하고자 합니다.
기술적 가치 무엇일까?
•
AutoRAG에서 현재 지원하는 12가지의 모듈로 960가지의 조합을 (임베딩 모델, 언어모델은 조합에서 제외) 활용하여 최적의 RAG 파이프라인 생성 자동화 가능
•
AutoRAG는 딥러닝 생태계(Hyper Parameter Tunning, Neural Network Search)의 AutoML처럼 RAG의 파이프라인을 자동으로 최적화
•
AutoRAG는 설정파일(.yaml)을 간단히 수정하는 것 만으로 파이프라인 구성 가능
•
AutoRAG를 실행하면 복잡한 RAG 파이프라인의 각 단계들을 자동으로 평가하여 최적의 파이프라인을 제시함
•
각 단계별로 평가 결과를 저장하여, 어느 단계에서 가장 큰 성능 하락이 일어나는지, 어떠한 모듈이 가장 성능 향상을 가져왔는지 실시간 확인 가능
•
최적의 파이프라인 찾게 되면, 곧바로 fastAPI 서버로 실행하여 API 서비스로 적용 가능
•
새롭게 찾은 최적의 파이프라인을 yaml 파일로 생성하여, 본인의 RAG 파이프라인을 쉽게 공유 가능
•
RAG 기반의 AI 애플리케이션 개발에 필요한 데이터 플랫폼 자동화에 혁신적인 기여를 할 것으로 판단
•
궁극적으로는 AICC 영역에서 AI 챗봇 서비스를 위한 최적의 RAG 파이프라인 생성을 위한 자동화 기술로 활용할 예정.
이 과제를 통해 성장할 수 있는 포인트는?
•
LLMOps 전체영역에서 RAG 파이프라인 생성을 위한 핵심기술 내재화 가능
•
AutoRAG를 AI 챗봇서비스에 상용화할 수 있는 경험 (/w Devocean 챗봇)
03 이런 Fellows를 찾아요!
•
본 과제에서 제시한 문제를 자기 주도 / 완결적으로 도전하여 해결하고자 하는 의지
•
새로운 기술에 대한 빠른 러닝커브
•
LLMOps 영역에서의 챗봇 기술 설계/개발 경험
•
과제 수행과정을 통해 다양한 아이디어 기반으로 특허/논문 도출
Reference
FAQ
Q1. ‘AutoRAG' 기술을 적용하여 고객의 다양한 데이터셋에 최적화된 RAG 파이프라인을 찾아내고, 이를 챗봇에 적용하여 생성되는 응답에 대해 평가/모니터링 솔루션 구축하여 AutoRAG 성능효과를 증명하고자 합니다. ’AutoRAG에 탑재된 기능을 추가적으로 고도화하고, 평가 모니터링 솔루션 구축 까지가 해당 과제의 목표인지 혹은 AutoRAG는 적용만 하고 ''평가/모니터링 솔루션 구축''을 주 과제의 목표로 하시는지 헷갈려 질문드립니다!즉, Advanced RAG 자동화 -> Modular RAG 자동화로 고도화하는 것을 본 과제의 목표라고 생각하면 될까요?
A1. 저희가 준비한 데이터셋(AIShop 데이터, e.g. 배달의민족, 아프니까 사장이다. 요기요)에 대해 AutoRAG를 이용하여 Optimal RAG Pipeline 을 생성하고,이를 RAG 챗봇으로 연동하여 LLM 평가 & E2E 모니터링 까지 수행하고자 합니다. 이를 위한 기반 플랫폼과 그 위에서 동작하기 위한 챗봇 구성은 어느 정도 개발되어 있기 때문에 업의 양이 많지만,이번 과제를 통해 충분히 진행할 수 있다고 판단하고 있습니다. Modular RAG는 이번 과정에서는 진행하지 않습니다.
Q2. 과제를 보면, 현재 제작하고 계시는 Devocean 챗봇에 RAG 시스템을 도입해, 사용자의 다양한 데이터에 대해 일관성 있는 답변을 만들고자 하는 것으로 이해를 했습니다. '사용자의 다양한 데이터' 같은 경우, Devocean 사이트에 게시물과 같은 글에 대한 데이터만을 한정해서 말씀하시는 것인지, 아니면 인터넷에 있는 정말 다양한 도메인에 대한 데이터를 포함해서 말씀하는건지 궁금합니다.
A2. 위에서 답변 드린 것처럼 AIShop 데이터셋을 이미 확보했고, 이 데이터셋을 이용하여 진행할 계획입니다. AutoRAG의 핵심은 다양한 데이터셋 별로 최적화된 RAG 파이프라인을 찾는 과정이 어렵고 이를 자동화함으로써 많은 시간/노력을 줄여줄 수 있다는 것입니다.AIShop 데이터에는 소상공인들이 장사하는데 필요한 여러 노하우 기술, 노무사 관련 법률데이터, 그들의 애환(?)이 담긴 데이터가 많이 있고, 이 데이터를 이용한 최적의 RAG 파이프라인을 찾고자 합니다.
Q3. ''AutoRAG를 활용한 rag 자동화를 위한 최적화 기술 개발'' 부분에서, ''특정 도메인에 대한 AutoRAG를 최적화 하는 것''이 해당 과제에서 추구하고 있는 방향성이 맞는지, 만일 맞다면 데이터 구축 같은 경우는 임의로 한 도메인에 대해서 연구 계획서를 작성하면 될지 여쭤보고 싶습니다.만일 해당 방향성이 아니라면 도메인 별 최적화 기술 개발이 아니라 ''도메인에 상관없이 일관성(일반화) 있는 모델 고도화''를 말씀하시는 것인지 궁금합니다.
A3. 이번 과제는 AIShop 데이터를 기반으로 하는 소상공인을 위한 특정 비즈니스 도메인에서의 RAG 챗봇을 연구/개발이 주 목적입니다.이 부분이 검증되면, 다양한 고객의 범용 데이터셋으로 AutoRAG 자동화하여 AI 애플리케이션을 위한 Knowledge Base 플랫폼 구축으로 발전시킬 수 있을 듯 합니다.
참고로 이를 위해 필요한 기술을 하단에 공유드립니다. 미리 살펴보시면 도움이 될 것 같습니다.
Q4. AI shop 데이터를 기반으로 최적의 RAG 파이프라인을 찾는 과정에서, AutoRAG의 기능들(ex.모듈,노드계산방법)을 추가해서 기존의 AutoRAG를 고도화 및 최적화하는 방향이 연구 과제인건지, 그렇다면, AutoRAG에 탑재할 수 있는 추가적인 아이디어들에 대해서 연구 계획서를 작성하면 되는건지 궁금합니다.
A4. AutoRAG에 사용되는 모듈 평가 방법에 대해 리서치 해보고 그를 바탕으로 적용 및 확장하는 것을 기본으로 다룰 예정입니다. 탑재할 수 있는 추가적인 아이디어를 제시해주는 것도 좋은 아이디어가 될 듯 합니다.
Q5. 임베딩이랑 llm 모델은 고려 안해도 되는지 여쭤보고 싶고, 어떤 모델 사용하실 계획이실까요?
A5. 현재는 OpenAI에서 제공하는 모델을 중점으로 사용할 예정입니다. llama3 한국어 파인튜닝된 모델이 출시되면 사용해볼 예정입니다.
Q6. 최적화된 Pipeline을 찾고, '평가 및 모니터링'' 하는 과정까지도 연구 계획서의 일환인건지 여쭤보고 싶습니다. 이를테면, 사용하시려는 평가 지표가 따로 있는 상황인지 아니면, 저희가 연구계획서에 구체적으로 어떤 평가지표를 사용할 것인지까지가 연구계획서에 들어가는 것인지 여쭤보고 싶습니다.
A6. RAG 파이프라인 평가는 오픈소스 프로젝트 중 RAGAS를 통해 할 예정입니다.